Ученые из ФИЦ Биотехнологии РАН нашли в геноме риса короткие диспергированные повторы при помощи метода HDRSM. Раньше похожий способ использовался для поиска сдвига рамки считывания в кодирующих белки участках геномов. Результаты работы были опубликованы в BMC Bioinformatics.
| В геномах живых организмов существуют участки, которые могут вырезать себя из одного места и «переехать» в другое. Такие последовательности называются транспозонами. Обычно транспозоны имеют «транспорт» при себе. Но некоторые участки не могут перемещаться сами, а вместо этого используют «машину» соседних транспозонов, как автостопщики. К ним относятся короткие диспергированные повторы, или SINE (от английского Short interspersed nuclear element) — участки длиной около 500 нуклеотилдов, появившиеся из-за обратной транскрипции коротких РНК.
Поскольку эти участки не кодируют важные для выживания организма белки, они легко накапливают мутации, поэтому искать их в геноме очень сложно. Однако транспозоны могут вызывать мутации, перемещая гены и повреждая генетический материал, поэтому их важно изучать в сельскохозяйственных культурах. За открытие транспозонов у кукурузы Барбара Макклинток в 1983 году получила Нобелевскую премию. Теперь же российские ученые исследовали SINE у риса Oryza sativa.
Для этого они применили метод HDRSM, который учитывает сочетания соседних символов, чтобы составить позиционную весовую матрицу семейства SINE. При помощи этой матрицы на основе множественного выравнивания родственных последовательностей биоинформатики нашли 14 030 новых копий SINE из 39 семейств и установили их границу. |
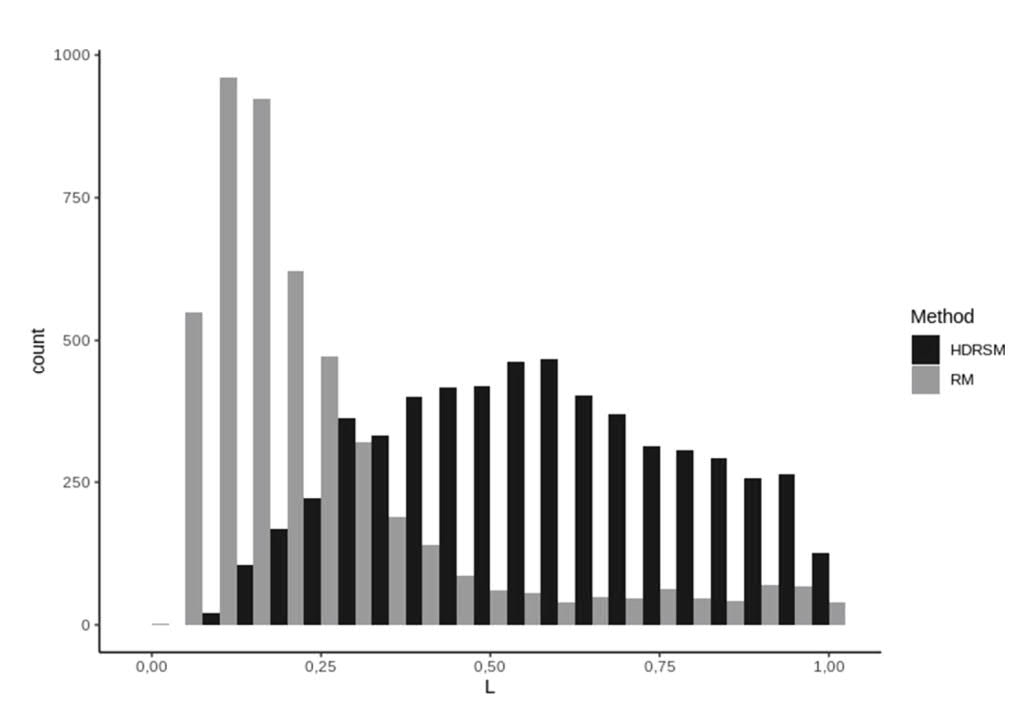
Распределение процента длин копий SINE повторов относительно |
Для сравнения ученые применили к тому же геному другой метод— программу RepeatMasker. 5704 из этих копий стандартным способом обнаружить не получилось. Однако у каждого метода нашлись свои преимущества. Оказалось, что RepeatMasker лучше ищет короткие копии, похожие на оригинал, а HDRSM удается обнаружить более длинные варианты, но сильнее отошедшие от первоначального. Биоинформатики заключили, что для более подробного анализа лучше применять оба метода, так как они дополняют друг друга.